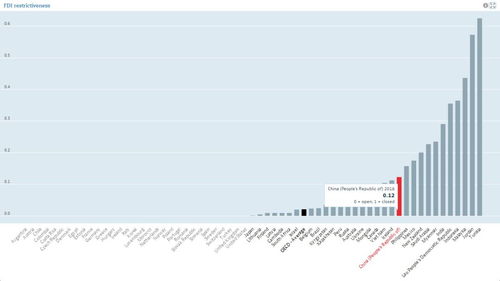
Hadoop是一個開源的、由Apache軟件基金會所開發(fā)的分布式計算框架。其核心設計靈感來源于Google的MapReduce和Google File System論文。Hadoop旨在通過簡單的編程模型,在由大量廉價硬件組成的集群中,對海量數(shù)據(jù)集進行可靠的、可擴展的分布式處理。它讓用戶無需深入了解分布式系統(tǒng)的底層細節(jié),就能輕松開發(fā)出處理PB級別數(shù)據(jù)的應用程序。
Hadoop的核心生態(tài)系統(tǒng)主要由以下幾個關鍵組件構成:
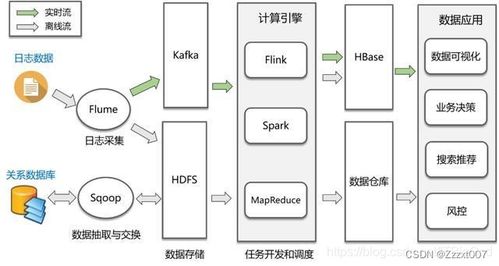
- Hadoop分布式文件系統(tǒng):一個高度容錯的分布式文件系統(tǒng),設計用于在低成本硬件上運行。它將大數(shù)據(jù)文件切割成塊,并分散存儲在整個集群的多個節(jié)點上,默認提供三副本冗余機制來保證數(shù)據(jù)安全。
- Hadoop MapReduce:一個用于并行處理海量數(shù)據(jù)集的編程模型和軟件框架。其處理過程分為兩個階段:Map(映射)階段對輸入數(shù)據(jù)進行篩選和排序,Reduce(歸約)階段對Map的結果進行匯總,從而得出最終結果。
- Hadoop YARN:在Hadoop 2.0中引入的資源管理和作業(yè)調(diào)度平臺,它將資源管理與具體的計算框架解耦,使得Hadoop可以運行除MapReduce之外的其他計算模型,大大提升了集群的利用率和靈活性。
除了核心組件,豐富的子項目構成了強大的Hadoop生態(tài)系統(tǒng),例如用于數(shù)據(jù)倉庫的Hive,用于分布式數(shù)據(jù)庫的HBase,用于數(shù)據(jù)采集的Flume和Sqoop,以及用于協(xié)調(diào)分布式服務的ZooKeeper等。
Hadoop的應用場景極其廣泛,已成為各行各業(yè)處理大數(shù)據(jù)的首選平臺:
- 互聯(lián)網(wǎng)與社交媒體:用于用戶行為分析、廣告精準投放、推薦系統(tǒng)(如電商產(chǎn)品推薦、新聞資訊推送)和社交網(wǎng)絡關系挖掘。
- 金融行業(yè):應用于欺詐檢測、風險建模、信用評估和股票市場趨勢分析。
- 電信行業(yè):處理通話詳單,進行網(wǎng)絡質(zhì)量監(jiān)控和用戶位置分析。
- 醫(yī)療與生命科學:用于基因序列分析、疾病研究和醫(yī)療影像存儲分析。
- 零售與物流:優(yōu)化供應鏈、分析銷售趨勢、管理庫存和規(guī)劃物流路線。
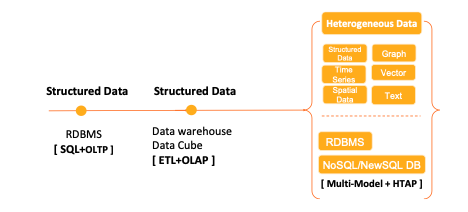
值得注意的是,雖然Hadoop在在線數(shù)據(jù)處理領域有廣泛應用(例如,通過HBase支持低延遲的隨機讀寫,或通過Spark Streaming進行近實時流處理),但其最初的設計重點在于離線批處理。傳統(tǒng)的Hadoop MapReduce模型在處理海量歷史數(shù)據(jù)、進行復雜ETL(提取、轉換、加載)和批量分析方面表現(xiàn)卓越,但其高延遲的特性并不適合需要毫秒級響應的在線交易處理業(yè)務。
典型的在線交易處理系統(tǒng),如銀行核心交易系統(tǒng)或電商訂單系統(tǒng),要求極高的并發(fā)性、強一致性和低延遲,通常由關系型數(shù)據(jù)庫或新型的分布式關系數(shù)據(jù)庫來承擔。而Hadoop更多地扮演著“數(shù)據(jù)倉庫”或“數(shù)據(jù)湖”的角色,存儲來自OLTP系統(tǒng)的歷史交易數(shù)據(jù),并對其進行后續(xù)的批量分析、數(shù)據(jù)挖掘和報表生成,為商業(yè)決策提供支持。這種分工協(xié)作的模式——OLTP系統(tǒng)處理前端交易,Hadoop生態(tài)系統(tǒng)進行后端大數(shù)據(jù)分析——構成了現(xiàn)代企業(yè)典型的數(shù)據(jù)處理架構。
Hadoop作為大數(shù)據(jù)技術的先驅和核心,以其高可靠性、高擴展性、高容錯性和低成本的優(yōu)勢,成功解決了海量數(shù)據(jù)的存儲和計算難題,為大數(shù)據(jù)分析鋪平了道路,并持續(xù)推動著數(shù)據(jù)驅動決策時代的到來。